本文大部分是背景介绍,本来想一气呵成,但发现要讲的东西有点多,遂分成了两篇来写。
Mara Bos 关于并发主题的新书 Rust Atomics and Locks 最近可以免费在线阅读了,这位 Rust Library team 的 Leader 自不必多说,对 Rust 的理解(贡献)非是常人可比,而这次 Mara 博士这次的慷慨更是让手头常年拮据学生党(鄙人)直呼老铁 666!耶,是官方的白嫖!
玩笑差不多了,说正事。
尽管鄙人的英语是中国人水平,但为了学点 Rust,困难可以克服(感谢谷歌翻译+DeepL+ChatGPT),这本书不长,但想要读透,真正领会作者的思想,要花好多功夫。在一众翻译软件的帮助下,我简单阅读了这本书的前几章内容,其中第一个令我印象深刻的内容当属第 3 章中提到的也是我们今天的主题:Happened-before 关系。
要讨论 Happened-before 关系,说来话长,让我们保持耐心,先从简单的计算机历史说起。
最初的计算机工作非常简单,只要把一些简单繁琐的计算任务搞定即可,在真空管和穿孔打卡的时代,程序员是把程序写到纸上,你没看错,是纸,然后在纸上穿孔,如此反复操作,直到穿成厚厚的一摞,再把这一摞交给计算机,计算机计算结果打印出来,然后程序员拿到打印结果。
这就是最开始的 IO。
用今天的眼光看那时的程序员也太不容易了,纸上编程确实有助于学习编码和思考代码逻辑,但如果真要把干活的程序写在纸上再去穿孔才能执行,这种繁琐、浪费是现在的程序员所无法想象的(谁愿意天天穿孔),你可能会问:如果我就运行自己的程序行不行,答案是不行!在当时计算机的资源是相当昂贵的,没有那么多机器让你一个人玩,就像买东西太贵选择拼单一样,你写程序也要和人拼计算机,所谓批处理就是这么一回事,名字起得挺高深,实际上背后一把辛酸泪。
这样的 IO 用脚趾头想都能想到肯定会和 CPU 的速度存在巨大差异,CPU 的计算时间非常少而等待 IO 结束的时间却很多。所以为了 让 CPU 更累 更合理地利用 CPU 计算资源,我们就得想个办法,看能不能「偷」点时间出来。后来不知道哪位天使大哥/大姐想到了一个鬼点子:我们可以把内存划分为多个部分(日子宽裕了,内存也比以前大了,可以让更多程序用了),不同的程序可以使用各自的内存部分互不干涉,这些单独的程序就是所谓的进程。然后我们给 CPU 再加上一个超能力:跨进程切换执行。这样就有戏法可以玩了:当某个进程进行磁盘 IO 的时候,CPU 就可以切换到另外一个进程执行(闲着也是闲着,不如干点别的活),这样就 让 CPU 更累 偷出了本来可以摸鱼(等待 IO)的时间来干活(运行其他进程),我们的目的达到了!(能力越大,责任就越大嘛~)
怎么给 CPU 加上跨进程切换执行的超能力呢?请看三板斧:
- CPU 时间片:现在我们有很多进程,所以对于每个进程如何执行,需要有个规定──每一次切换进程后,CPU 只会工作一段时间,然后又切换到另外一个进程,再执行一段时间。我们把 CPU 切换进程的这个时间段叫做“时间片”。
- 程序计数器:CPU 经过一圈切换后还会切换回最开始的进程继续执行(对每个进程都是如此),所以它需要知道进程已经执行到了哪一步才好接着执行,程序计数器应运而生,它会记住进程执行到的位置。有了这个就可以继续执行了。
- 栈指针:程序计数器解决了记忆程序(代码)执行到的位置,但是每个进程还持有操作系统分配给它的内存资源,这玩意对每个进程是独立的,因此也需要记录,所以我们用栈指针来记录操作系统给它的内存资源地址。
这三板斧下去,CPU 再也不好摸鱼了,比起以前,那效率是高多了,但是人类对于极致的追求是无止境的,大家慢慢发现切换进程这个操作本身居然挺费时间,如果每个进程都有很多 IO,那么 CPU 的时间都被切换进程浪费掉了,然后还什么都没做,这不是又让 CPU 闲着了吗?不行,必须要解决!
这只是一个缺点,相关的缺点还有很多,不一一列举了。
进程切换成本这么高,一部分的原因是进程太「重」了,每切换一次上面的三板斧都得顾及到,那么让它变得小一点不就好了吗?这就是线程:我们让一个进程创建很多个线程,然后让线程来做以前进程的工作,现在 CPU 会在线程而不是进程之间来回切换,由于线程更小,时间片也分得更小,以至于多个线程之间切换执行成本也小了,同时 CPU 等待 IO 的几率也更加小了。一举多得。
线程版本的三板斧:
- 程序计数器,表示当前线程执行指令的位置。
- 保存变量的寄存器。
- 栈。每个线程的栈记录了函数调用的记录,并反映了当前线程的执行点。
技术领域有一句名言:没有银弹。意思是不管什么问题,没有万能解决方案。多线程也不是没缺点,对程序员来说最直观的感受就是:多线程编程更难。为什么?因为在多线程编程的场景下,你会经常遇到「多个线程同时读取和修改同一个变量」的问题,而在 Rust 中,我们认为“这通常会导致未定义的行为(UB)”。
为什么“多个线程同时读取和修改同一个变量”会是个问题?这不是效率更高了吗?请看下面的伪代码:
data_race() { global x = 0 thread1 = thread { for i in 0..100 { x += 1; } }; thread2 = thread { for i in 0..100 { x += 1; } }; t1 = thread1.spawn(); t2 = thread2.spawn(); t1.join(); t2.join(); return x; }
之所以写伪代码是因为用 Rust 想写个有问题的程序着实不容易。
伪代码说明(虽然我希望这是不言自明的):
global x = 0表示x是个全局变量,每个线程都能看到并修改它的值thread1 = thread { for i in 0..100 { x += 1; } };表示thread1对x进行 100 次加 1 操作,这是thread1的定义t1 = thread1.spawn();则是启动thread1,thread1自此开始执行thread1.join();表示当前线程(主线程)将一直等待thread1执行结束thread2上述一切同理
请猜想下,这段程序执行到 return x; 时,x 的值会是多少?
答案是:只有天知道,理论上在 100-200 之间的任何整数值都有可能。
你可能会问:x 不是 200 吗?
x 不一定会是 200,这就是多线程编程的吊诡之处,很反直觉。
更反直觉的还在后面。
试想下面的过程:
(1)CPU 时间片先分给 thread1 执行,假设代表 x 这个变量的寄存器在 thread1 中执行累加到了 50,此时恰巧时间片用完了,而存放在寄存器中的值 50 还没来及写入实际的物理内存。
(2)因为时间片用完了,CPU 现在分配给 thread2,由于 thread1 算出来的值并没有写回内存,所以实际上此时 thread2 还是从 x = 0 开始进行加 1 操作,这次我们假设分给它的时间片够进行 60 次加 1 操作,之后 thread2 将得到的 x = 60 写入实际的物理内存。
(3)时间片再度分配给 thread1,thread1 开始执行它在上一个时间片结束时没有执行完的工作,将 x = 50 写入实际的物理内存,计算机严格按照代码执行指令,但此时问题出现:thread1 计算并写入的 x = 50 会把 thread2 计算并写入的 x = 60 覆盖掉。而每次执行程序,上述情况的发生总不会完全一致,比如时间片的大小就不是能完全确定的,相当于每次都有微调,这就是多次执行相同的代码得到的结果却完全不一致的原因。
其实真实的过程比这复杂得多,这里进行了简化以方便讨论概念。
如何解决这样的问题?先来看问题出在哪里。我们可以发现上面程序过程中的关键点是:每个线程的 计算 x 的值 和 把算好的值存入物理内存 这两个操作之间是 不连续的,这样就给了其他线程进来搞破坏的可趁之机。
如果在单个线程中,计算值和把算好的值存入内存这两个操作连续进行是很自然的,自然到你根本不会意识到它们还可以不连续,这是你编程时的默认心智模型,如果这一条都不成立大家也就不用编码了。
其实这里面还有指令重排的事,别以为你「看到」的就是「真相」。
但是在多线程环境中,这就成为了问题,为了灵活和性能,多线程编程的自由度更高。如果多线程编程要强行规定线程间的执行顺序、线程内的指令执行顺序,那样还有意义吗?还不如继续优化多进程。
好,我们现在遇到了一个“既要…还要…”的问题:我们既要留住多线程的灵活,又要让它在某些时候不那么灵活,有没有两全法呢?有,原子操作!
原子操作是什么呢?我认为最通俗易懂的说法是:要么不做,要么全做。不过我的总结不够规范,咱们还是来看专业人士(Mara Bos 博士)是怎么表述这个概念的:
The word atomic comes from the Greek word ἄτομος, meaning indivisible, something that cannot be cut into smaller pieces. In computer science, it is used to describe an operation that is indivisible: it is either fully completed, or it didn’t happen yet.
原子这个词来自希腊语 ἄτομος,意思是不可分割的,不能被切割成更小的部分。在计算机科学中,它被用来描述一个不可分割的操作:它要么完全完成,要么还没有发生。
However, atomic operations do allow for different threads to safely read and modify the same variable. Since such an operation is indivisible, it either happens completely before or completely after another operation, avoiding undefined behavior.
原子操作允许不同的线程安全地读取和修改同一个变量。由于原子操作是不可分割的,它要么完全发生在另一个操作之前,要么完全发生在另一个操作之后,这样就避免了 UB。Atomic operations are the main building block for anything involving multiple threads. All the other concurrency primitives, such as mutexes and condition variables, are implemented using atomic operations.
原子操作是涉及多线程的任何事物的主要构建块。所有其他并发原语,例如互斥量和条件变量,都是使用原子操作实现的。
In Rust, atomic operations are available as methods on the standard atomic types that live instd::sync::atomic. They all have names starting withAtomic, such asAtomicI32orAtomicUsize. Which ones are available depends on the hardware architecture and sometimes operating system, but almost all platforms provide at least all atomic types up to the size of a pointer.
在 Rust 中,原子操作可以作为存在于std::sync::atomic中的标准原子类型的方法。它们的名称都以Atomic开头,例如AtomicI32或AtomicUsize。哪些可用取决于硬件架构,有时取决于操作系统,但几乎所有平台都至少提供所有原子类型,最大为指针大小。
Unlike most types, they allow modification through a shared reference (e.g.,&AtomicU8). This is possible thanks to interior mutability, as discussed in “Interior Mutability” in Chapter 1.
与大多数类型不同,它们允许通过共享引用进行修改(例如&AtomicU8)。这要归功于内部可变性,正如第 1 章“内部可变性”中所讨论的那样。
我们可以看到“原子操作是不可分割的”,放在我们的例子中这也就意味着我们可以通过原子操作,让线程的 计算 x 的值 和 把算好的值存入物理内存 之间是 不可分割的,那么也就不会出现前文中所述的错误,x 就会是 200。
Rust 是一门标榜“安全”的语言,既然多线程编程中会有“不安全”的场景出现,那么 Rust 肯定要考虑如何解决,不过相比 The book 中其他主题的 Rust 安全特色(所有权、借用检查等),我读到 Rust Atomics and Locks 后面只觉得在多线程编程方面,Rust 还是很明显地抄了不少别人(C++)的东西,例如下面 Mara Bos 博士话锋一转,开始讨论起了另一个概念:
But, before we can dive into the different atomic operations, we briefly need to touch upon a concept called memory ordering:
但是,在我们深入研究不同的原子操作之前,我们需要简单地谈谈一个叫做内存排序的概念:
Every atomic operation takes an argument of typestd::sync::atomic::Ordering, which determines what guarantees we get about the relative ordering of operations. The simplest variant with the fewest guarantees isRelaxed.Relaxedstill guarantees consistency on a single atomic variable, but does not promise anything about the relative order of operations between different variables.
每个原子操作都有一个类型为std::sync::atomic::Ordering的参数,它决定了我们对操作的相对顺序有什么「保证」。而「保证」最少的、最简单的变体是Relaxed。Relaxed仍然保证单个原子变量的一致性,但不保证不同变量之间的相对操作顺序。
What this means is that two threads might see operations on different variables happen in a different order. For example, if one thread writes to one variable first and then to a second variable very quickly afterwards, another thread might see that happen in the opposite order.
这意味着两个线程可能会看到对不同变量的操作以不同的顺序发生。例如,如果一个线程首先写入一个变量,然后很快写入第二个变量,则另一个线程可能会看到以相反顺序发生的情况。
我之前说有更反直觉的东西,这不现在看到了?为什么第二个线程可能看到以相反顺序发生的情况?
Processors and compilers perform all sorts of tricks to make your programs run as fast as possible. A processor might determine that two particular consecutive instructions in your program will not affect each other, and execute them out of order, if that is faster, for example. While one instruction is briefly blocked on fetching some data from main memory, several of the following instructions might be executed and finished before the first instruction finishes, as long as that wouldn’t change the behavior of your program. Similarly, a compiler might decide to reorder or rewrite parts of your program if it has reason to believe it might result in faster execution. But, again, only if that wouldn’t change the behavior of your program.
处理器和编译器执行各种技巧以使您的程序运行得尽可能快。处理器可能会确定您程序中的两个特定的连续指令不会相互影响,并乱序执行它们(例如,如果这样更快的话)。虽然一条指令在从主存中获取一些数据时被短暂阻塞,但在第一条指令完成之前,可能会执行并完成以下几条指令,只要这不会改变程序的行为。同样,如果编译器有理由相信它可能会导致更快的执行,它可能会决定重新排序或重写程序的某些部分。但是,同样,前提是这不会改变您的程序的行为。Let’s take a look at the following function as an example:
让我们以下面的函数为例:
fn f(a: &mut i32, b: &mut i32) { *a += 1; *b += 1; *a += 1; }
Here, the compiler will most certainly understand that the order of these operations does not matter, since nothing happens between these three addition operations that depends on the value of
*aor*b. (Assuming overflow checking is disabled.) Because of that, it might reorder the second and third operations, and then merge the first two into a single addition:
在这里,编译器肯定会理解这些操作的顺序无关紧要,因为这三个取决于*a或*b的值的加法操作之间没有任何关联。(假设溢出检查被禁用)因此,它可能会重新排序第二个和第三个操作,然后将前两个合并为一个加法:
fn f(a: &mut i32, b: &mut i32) { *a += 2; *b += 1; }
Later, while executing this function of the optimized compiled program, a processor might for a variety of reasons end up executing the second addition before the first addition, possibly because
*bwas available in a cache, while*ahad to be fetched from the main memory.
稍后,在执行优化编译程序的这个函数时,处理器可能由于各种原因在第一次加法之前结束执行第二次加法,这可能是因为*b在缓存中可用,而*a必须从主存提取。
Regardless of these optimizations, the result stays the same:*ais incremented by two and*bis incremented by one. The order in which they were incremented is entirely invisible to the rest of your program.
不管这些优化如何,结果都保持不变:*a增加 2,*b增加 1。它们递增的顺序对于程序的其余部分是完全不可见的。The logic for verifying that a specific reordering or other optimization won’t affect the behavior of your program does not take other threads into account. In our example above, that’s perfectly fine, as the unique references (&mut i32) guarantee that nothing else can possibly access the values, making other threads irrelevant. The only situation where this is a problem is when mutating data that’s shared between threads. Or, in other words, when working with atomics. This is why we have to explicitly tell the compiler and processor what they can and can’t do with our atomic operations, since their usual logic ignores interactions between threads and might allow for optimizations that do change the result of your program.
验证特定重新排序或其他优化不会影响程序行为的逻辑不会考虑其他线程。在我们上面的示例中,这完全没问题,因为独占引用 (&mut i32) 保证没有其他任何东西可以访问这些值,从而使其他线程无关紧要。唯一会出现问题的情况是在改变线程之间共享的数据时。或者,换句话说,在使用原子时。这就是为什么我们必须明确地告诉编译器和处理器它们可以用我们的原子操作做什么和不能做什么,因为它们通常的逻辑会忽略线程之间的交互,并且可能允许进行确实会改变程序结果的优化。
The interesting question is how we tell them. If we wanted to precisely spell out exactly what is and isn’t acceptable, concurrent programming might become exceedingly verbose and error prone, and maybe even architecture-specific:
有趣的问题是我们如何告诉他们。如果我们想准确地说明什么是可接受的,什么是不可接受的,并发编程可能会变得非常冗长和容易出错,甚至可能是特定于体系结构的:
let x = a.fetch_add(1, Dear compiler and processor, Feel free to reorder this with operations on b, but if there's another thread concurrently executing f, please don't reorder this with operations on c! Also, processor, don't forget to flush your store buffer! If b is zero, though, it doesn't matter. In that case, feel free to do whatever is fastest. Thanks~ <3 );
Instead, we can only pick from a small set of options, represented by the
std::sync::atomic::Orderingenum, which every atomic operation takes as an argument. The set of available options is very limited, but has been carefully picked to fit most use cases well. The orderings are very abstract and do not directly reflect the actual compiler and processor mechanisms involved, such as instruction reordering. This makes it possible for your concurrent code to be architecture-independent and future-proof. It allows for verification without knowing the details of every single current and future processor and compiler version.
相反,我们只能从一小组选项中选择,由std::sync::atomic::Ordering枚举表示,每个原子操作都将其作为参数。可用选项集非常有限,但经过精心挑选以适合大多数用例。排序非常抽象,并不直接反映所涉及的实际编译器和处理器机制,例如指令重新排序。这使您的并发代码可以独立于体系结构且面向未来。它允许在不知道每个当前和未来处理器和编译器版本的详细信息的情况下进行验证。The available orderings in Rust are:
Rust 中可用的排序是:
- Relaxed ordering: Ordering::Relaxed
- Release and acquire ordering: Ordering::{Release, Acquire, AcqRel}
- Sequentially consistent ordering: Ordering::SeqCst
In C++, there is also something called consume ordering, which has been purposely omitted from Rust, but is nonetheless interesting to discuss as well.
在 C++ 中,还有一种叫做 consume ordering 的东西,它在 Rust 中被故意省略了,但讨论起来也很有趣。
在这一大段里我们来捞点干的,大意是编译器会优化代码,导致指令执行顺序和代码表示的顺序不一定一致,而这一点在多线程环境下被放大了。不管是否有指令重排,第一个线程实际上并不关心,因为不会影响它的执行结果,而假如发生了指令重排,使第一个线程真实的执行顺序变得和原来相反,那么第二个线程就看到了相反顺序的发生情况,如果第二个线程的操作对第一个线程的操作顺序有所依赖,这就会出现问题。所以在某些特殊场合,我们需要有能力对代码/指令的执行顺序有所限制,如果你不想做上面 Mara 博士举例的“面向协议编程”,内存排序则是你的救星。
The different memory ordering options have a strict formal definition to make sure we know exactly what we’re allowed to assume, and for compiler writers to know exactly what guarantees they need to provide to us. To decouple this from the details of specific processor architectures, memory ordering is defined in terms of an abstract memory model.
不同的内存排序选项有一个严格的正式定义,以确保我们确切地知道我们被允许假设什么,并让编译器编写者确切地知道他们需要为我们提供什么保证。为了将其与特定处理器架构的细节分离,内存排序是根据抽象内存模型定义的。
Rust’s memory model, which is mostly copied from C++, doesn’t match any existing processor architecture, but instead is an abstract model with a strict set of rules that attempt to represent the greatest common denominator of all current and future architectures, while also giving the compiler enough freedom to make useful assumptions while analyzing and optimizing programs.
Rust 的内存模型,主要是从 C++ 复制而来,不匹配任何现有的处理器架构,而是一个具有一组严格规则的抽象模型,试图代表所有当前和未来架构的最大公分母,同时也给出编译器有足够的自由在分析和优化程序时做出有用的假设。
We’ve already seen a part of the memory model in action in “Borrowing and Data Races” in Chapter 1, where we talked about how data races result in undefined behavior. Rust’s memory model allows for concurrent atomic stores, but considers concurrent non-atomic stores to the same variable to be a data race, resulting in undefined behavior.
我们已经在第 1 章的“借用和数据竞争”中看到了内存模型的一部分,我们在其中讨论了数据竞争如何导致未定义的行为。Rust 的内存模型允许并发原子存储,但将对同一变量的并发非原子存储视为数据竞争──导致未定义的行为。
计算机的难题 99% 是靠分层解决的,Rust 的内存模型也不例外,这里借鉴了 C++,或者说是编译器前后端/虚拟机的经验,不对某一具体处理器架构而是在这中间又加了一个抽象层,这样就能最大程度地保证灵活,除了多了一层翻译会有一点性能上的权衡以外没啥缺点。
激动,终于要谈到今天的主题──Happened-before 关系了,接着读:
The memory model defines the order in which operations happen in terms of happens-before relationships. This means that as an abstract model, it doesn’t talk about machine instructions, caches, buffers, timing, instruction reordering, compiler optimizations, and so on, but instead only defines situations where one thing is guaranteed to happen before another thing, and leaves the order of everything else undefined.
内存模型定义了操作发生的顺序,即 happens-before 关系。这意味着,作为一个抽象的模型,它不谈论机器指令、缓存、缓冲区、时间、指令重排、编译器优化等等,只定义了一件事在另一件事之前发生的情况,而对其他事情的顺序没有定义。
The basic happens-before rule is that everything that happens within the same thread happens in order. If a thread is executing
f(); g();, thenf()happens-beforeg().
基本的 happens-before 规则是同一线程内发生的所有事情都按顺序发生。如果线程正在执行f(); g();,那么f()happens-beforeg()。
这里我补充一些内容:
- Mara 博士原文是 happens-before,这是编程语言的用法,但我更想讨论的是 happened-before 事件间的关系,故引述原文的地方我不做改动,但在我自己叙述的时候使用后者
- 当 A 操作 happened-before B 操作的时候,操作 A 先于操作 B 执行,且 A 操作的结果对 B 来说可见。每个线程都可以执行不同的任务,但是当它们之间进行一些交互时,例如读写共享内存或发送和接收消息时,必须遵守一些规则。这些规则确保了在一个线程中发生的操作在另一个线程中变得可见之前已经完成。也就是说,在一个线程中发生的操作 happened-before 了在另一个线程中看到该操作
- happened-before 包含两种情况:
- 对于同一线程内的 happened-before,其等同于 sequenced-before(A sequenced-before B → 代表 A 的求值会先完成,之后才进行对 B 的求值)
- 对于不同线程内的 happened-before,其等同于 inter-thread happened before(A inter-thread happened before B → 如果操作 A happened-before 操作 B,则可以保证线程 1 中的操作 A 的执行对线程 2 中的操作 B 的执行是可见的,也就是说,操作 A 执行后对共享状态所做的修改对线程 2 可见)
Between threads, however, happens-before relationships only occur in a few specific cases, such as when spawning and joining a thread, unlocking and locking a mutex, and through atomic operations that use non-relaxed memory ordering.
Relaxedmemory ordering is the most basic (and most performant) memory ordering that, by itself, never results in any cross-thread happens-before relationships.
然而,在线程之间,happens-before 关系只发生在少数特定情况下,例如 spawn 线程和 join 线程、解锁和锁定互斥锁以及使用非Relaxed内存排序的原子操作。Relaxed内存排序是最基本(也是最高效)的内存排序,它本身不会导致任何跨线程的 happens-before 关系。To explore what that means, let’s take a look at the following example where we assume
aandbare concurrently executed by different threads:
为了探究这意味着什么,让我们看一下下面的示例,其中我们假设a和b由不同的线程同时执行:
static X: AtomicI32 = AtomicI32::new(0); static Y: AtomicI32 = AtomicI32::new(0); fn a() { X.store(10, Relaxed); // 1 Y.store(20, Relaxed); // 2 } fn b() { let y = Y.load(Relaxed); // 3 let x = X.load(Relaxed); // 4 println!("{x} {y}"); }
As mentioned above, the basic happens-before rule is that everything that happens within the same thread happens in order. In this case: 1 happens-before 2, and 3 happens-before 4, as shown in Figure 3-1. Since we use relaxed memory ordering, there are no other happens-before relationships in our example.
如上所述,基本的 happens-before 规则是同一线程内发生的所有事情都按顺序发生。在这种情况下:1 happens-before 2,3 happens-before 4,如图 3-1 所示。由于我们使用Relaxed内存排序,因此在我们的示例中没有其他 happens-before 关系。
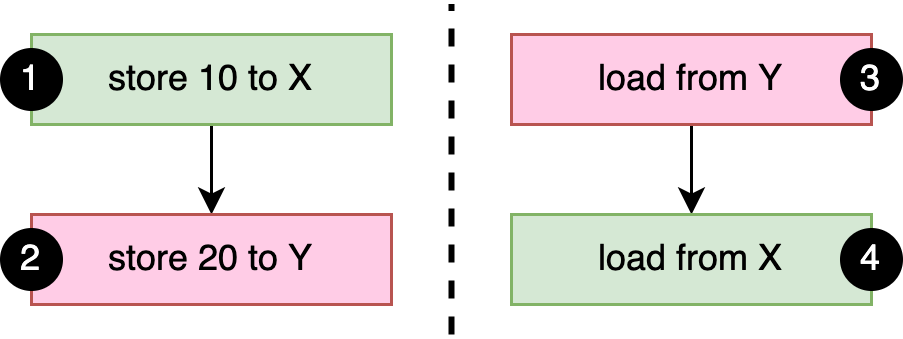
Figure 3-1. The happens-before relationships between atomic operations in the example code.
图 3-1 示例代码中原子操作之间的 happens-before 关系。
If either of
aorbcompletes before the other starts, the output will be0 0or10 20. Ifaandbrun concurrently, it’s easy to see how the output can be10 0. One way this can happen is if the operations run in this order: 3 1 2 4.
如果a或b中的任何一个在另一个开始之前完成,则输出将为0 0或10 20。如果a和b同时运行,很容易看出输出是10 0。发生这种情况的一种方式是操作按以下顺序运行:3 1 2 4。
More interestingly, the output can also be
0 20, even though there is no possible globally consistent order of the four operations that would result in this outcome. When 3 is executed, there is no happens-before relationship with 2, which means it could load either 0 or 20. When 4 is executed, there is no happens-before relationship with 1, which means it could load either 0 or 10. Given this, the output0 20is a valid outcome.
更有趣的是,输出也可以是0 20,即使没有可能导致此结果的四个操作的全局一致顺序。当 3 执行时,与 2 没有 happens-before 关系,也就是说它可以加载 0 或 20。当 4 执行时,与 1 没有 happens-before 关系,这意味着它可以加载 0 或 10。鉴于此,输出0 20是一个有效的结果。
The important and counter-intuitive thing to understand is that operation 3 loading the value 20 does not result in a happens-before relationship with 2, even though that value is the one stored by 2. Our intuitive understanding of the concept of “before” breaks down when things don’t necessarily happen in a globally consistent order, such as when instruction reordering is involved.
需要理解的重要且违反直觉的事情是,操作 3 加载值 20 不会导致与操作 2 为 happens-before 关系,即使该值是由操作 2 存储的。当事情不一定以全局一致顺序发生时,我们对“before”概念的直觉理解就会崩溃,例如当涉及指令重排时。
A more practical and intuitive, but less formal, understanding is that from the perspective of the thread executingb, operations 1 and 2 might appear to happen in the opposite order.
一种更实用、更直观但不太正式的理解是,从执行b的线程的角度来看,操作 1 和 2 的发生顺序可能相反。
迷糊了吧,我也迷糊了,我始终无法理解 0 20 是怎么成为一个有效结果的。首先输出 0,这意味着操作 4 在操作 1 之前发生;输出 20 则意味着操作 2 在操作 3 之前发生,而最关键的“基本的 happened-before 规则是同一线程内发生的所有事情都按顺序发生”,那么也就是说操作 3 在操作 4 之前发生,操作 1 在操作 2 之前发生,我是没有想得到是什么样的全局顺序能够满足这些要求,无论怎么想都有矛盾,Mara 博士也说这个例子中并没有能导致该结果的四个操作的全局一致顺序,所以如果还在这个方向思考,肯定是难以得到简单直观解释的。
让我卖个关子(其实已有伏笔),欲知后事如何,且听下回分解。